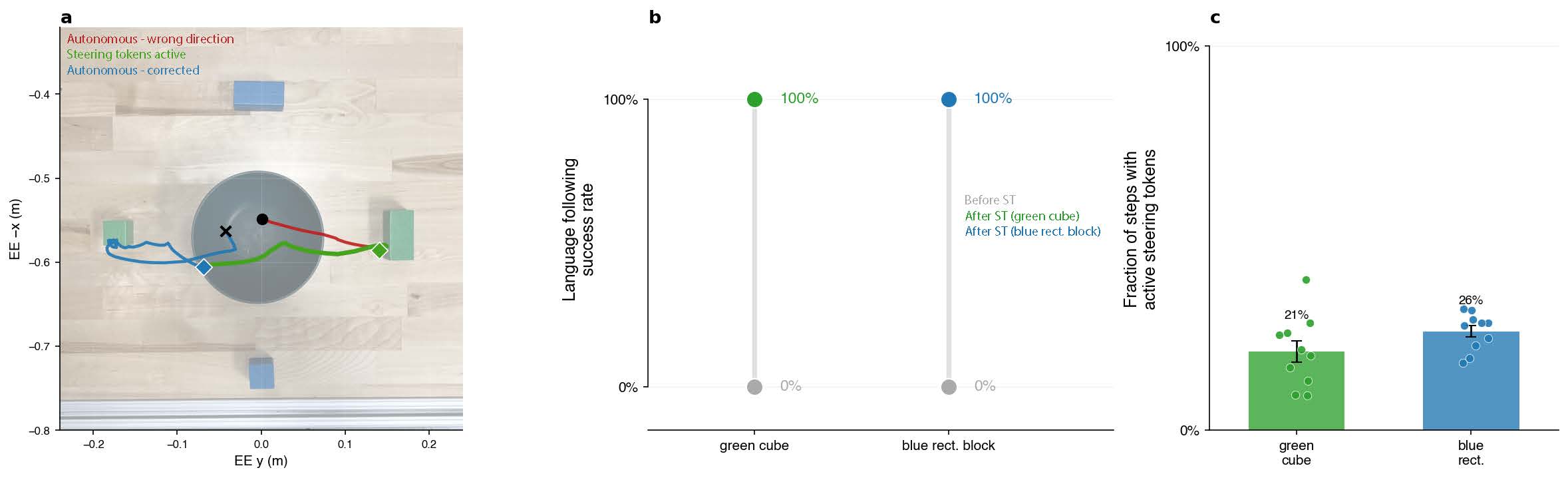
How Token Steering Works
Token Steering exploits the discrete autoregressive structure of frequency-domain (FAST) action tokenization. Rather than replacing robot trajectories through low-level control, TS injects user-generated steering tokens into the beginning of the autoregressive action sequence. The policy then autoregressively completes the remaining trajectory conditioned on the modified prefix — preserving smoothness, task consistency, and environmental adaptation.
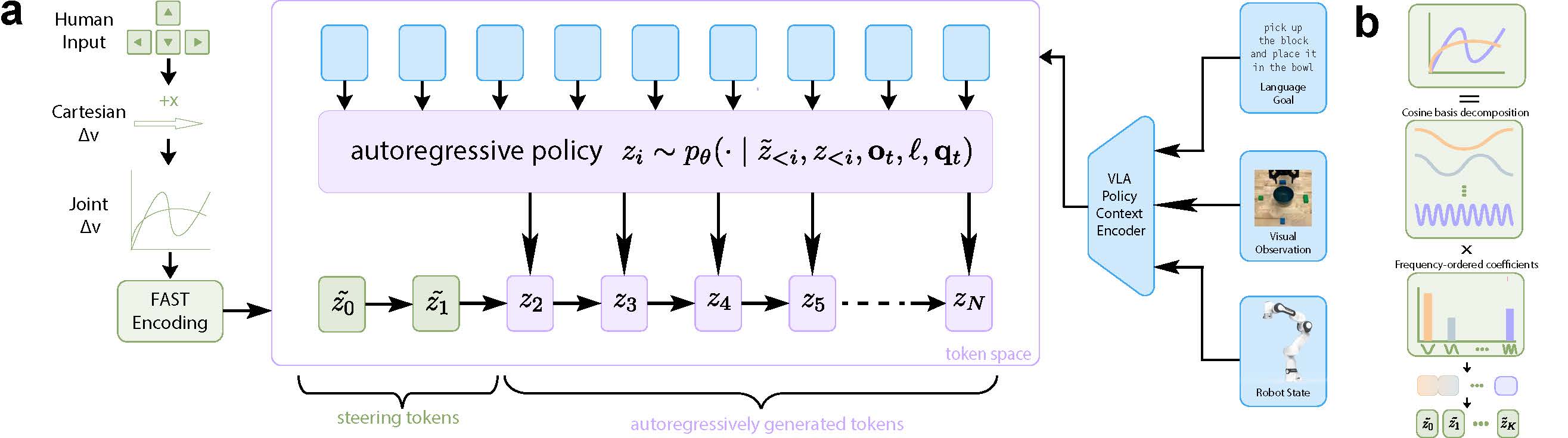
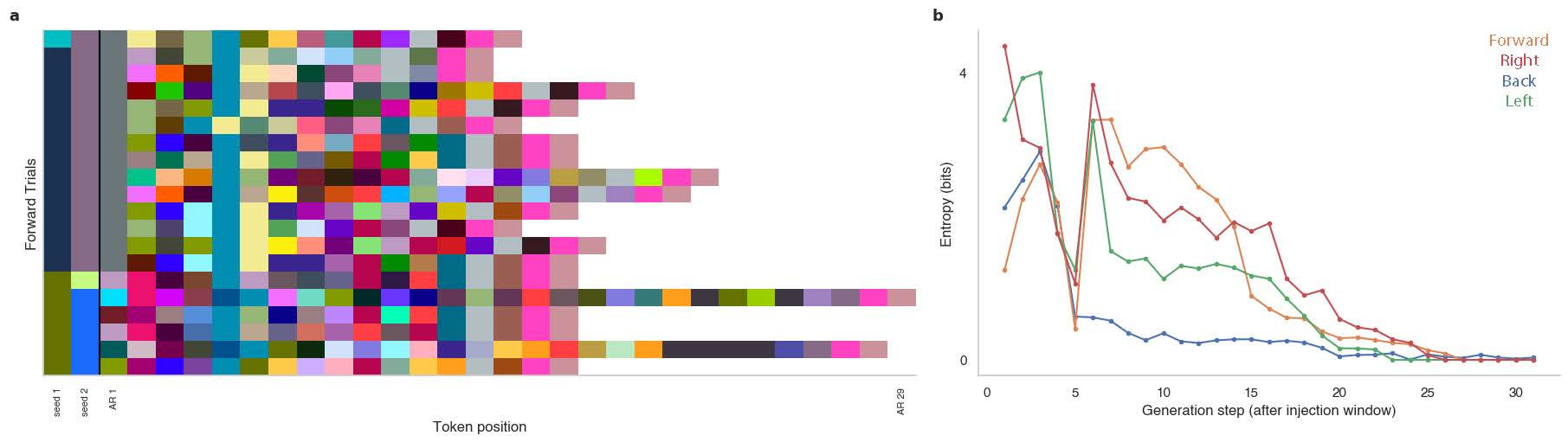
Figure 1. (a) A low-dimensional user input (keyboard arrow key) is converted to Cartesian velocity, transformed to joint velocity via inverse kinematics, FAST-tokenized, and injected as a prefix into the VLA's autoregressive action-token buffer. The policy autoregressively generates the remaining tokens conditioned on the modified prefix, visual observations, language instruction, and robot state. (b) FAST tokenization orders DCT coefficients from low to high frequency — early tokens encode coarse trajectory structure; later tokens refine fine motion details.
A keyboard direction encodes a 6-DOF intent vector u ∈ ℝ⁶, scaled to a Cartesian velocity v = mu.
Cartesian velocity → joint velocity via inverse kinematics → padded to action horizon H → FAST-encoded into discrete steering tokens z̃1:K.
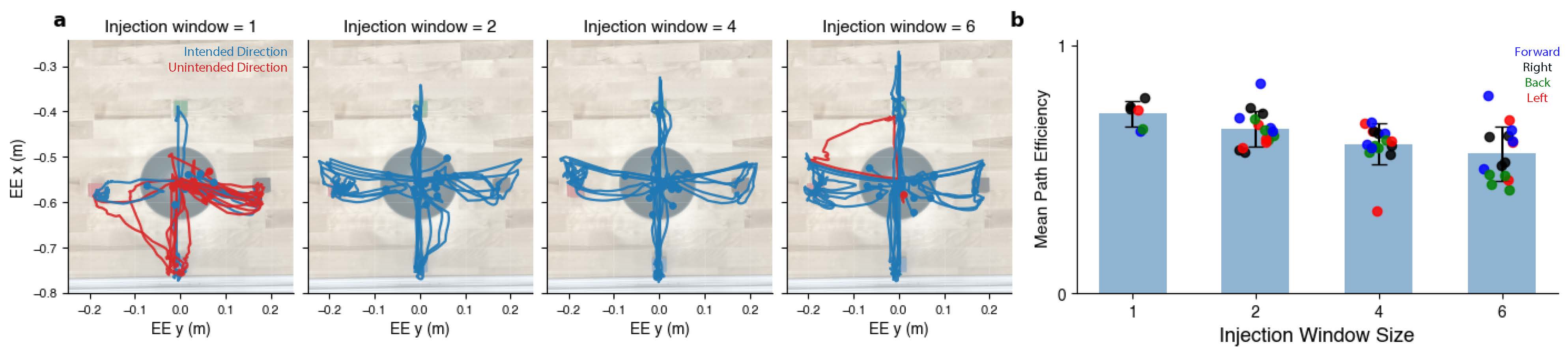
Only a small window of tokens [b, b+w) is replaced with steering tokens. The VLA autoregressively generates the rest — on-distribution and task-consistent.